Hi, ich hab wiedereinmal ein Problem:
Meine Textdatei wird zeilenweise durchsucht.
Alle Zeilen, die nicht mit einem Semikolon (' ; ') beginnen, werden per Substring zerlegt und die eigentlich wichtige Information herausgefiltert.
Die Textdatei ist ~so aufgebaut:
Network1Flag26_O = Befehl Sonstwas
;Network1Flag27_O = Befehl Sonstwas
Network1Flag26_O = Befehl Sonstwas
;Network1Flag27_O = Befehl Sonstwas;
;Network1Flag28_O = Befehl Sonstwas;
;Network1Flag29_O = Befehl Sonstwas;
Network1Flag30_O = Befehl Sonstwas;
Network1Flag31_O = Befehl Sonstwas;
TempFlag02_O = Befehl Sonstwas
TempFlag03_O = Befehl Sonstwas
TempFlag04_O = Befehl Sonstwas
TempFlag05_O = Befehl Sonstwas
Hier mal mein Quelltext:
Die rot markierten Passagen gefallen mir überhaupt nicht.
Das mit dem .trim() bzw. replace funktioniert überhaupt nicht. (siehe Anhang)
Es muss doch eine bessere Lösung geben, wie diese beiden Arrays zu vergleichen.
Hab mich jetzt schon stundenlang mit Arraylists, Hashmaps, zweidimensionalen Arrays usw herumgeschlagen. Ich checks einfach nicht.
Kann mir jemand evtl sagen, wie die Methode besser zu strukturieren ist?
Im Anhang mal die Ausgabe der Konsole mit dem Popup der doppelten Einträge.
mfg
Maddin
Meine Textdatei wird zeilenweise durchsucht.
Alle Zeilen, die nicht mit einem Semikolon (' ; ') beginnen, werden per Substring zerlegt und die eigentlich wichtige Information herausgefiltert.
Die Textdatei ist ~so aufgebaut:
Network1Flag26_O = Befehl Sonstwas
;Network1Flag27_O = Befehl Sonstwas
Network1Flag26_O = Befehl Sonstwas
;Network1Flag27_O = Befehl Sonstwas;
;Network1Flag28_O = Befehl Sonstwas;
;Network1Flag29_O = Befehl Sonstwas;
Network1Flag30_O = Befehl Sonstwas;
Network1Flag31_O = Befehl Sonstwas;
TempFlag02_O = Befehl Sonstwas
TempFlag03_O = Befehl Sonstwas
TempFlag04_O = Befehl Sonstwas
TempFlag05_O = Befehl Sonstwas
Hier mal mein Quelltext:
Code:
public static void Plausibilitaet(){
if(DateiChooser.uebergabe==null){
System.out.println("..." + DateiChooser.uebergabe);
DateiChooser.auswahlDatei();
}
ergebnis="";
try {
FileInputStream inputstream=new FileInputStream(DateiChooser.uebergabe);
InputStreamReader reader=new InputStreamReader(inputstream);
BufferedReader bff=new BufferedReader(reader);
String zeile=null;
String[] array = new String[800];
String[] array2 = new String[800];
int i=0;
while ((zeile = bff.readLine()) != null ) {
if(zeile.lastIndexOf("=") > 0 && !zeile.startsWith(";")){
String sub = zeile.substring(0, zeile.lastIndexOf("="));
sub.replaceAll(" ", "");
sub.trim();
System.out.println("SUB: " + sub + "#");
array[i] = sub;
array2[i] = sub;
i++;
}
befehlanzahl++;
}
// Hier meine Überprüfung, welche Einträge doppelt vorhanden sind
int a=0;
for(int x=0; x<array.length; x++){
for(int y=0; y<array2.length; y++){
if(array[x].equals(array2[y]) && x!=y){
System.out.println("X: " + x + "; Y: " + y + " " + array[x]);
ergebnis=ergebnis+array[x]+"\n";
a++;
}else{
}
}
}
} catch (Exception e) {
System.out.println("GEHT NICHT!");
System.out.println("exception: " +e);
}
Object[] options = {"Weiter..",
"Datei öffnen",
};
int n = JOptionPane.showOptionDialog(new JFrame(),
"Folgende Parameter kommen mindestens doppelt vor: \n\n"
+ ergebnis,
"Warnung!",
JOptionPane.YES_NO_OPTION,
JOptionPane.WARNING_MESSAGE,
null,
options,
options[1]);
switch (n){
case 0: System.out.println("Case 0 ");
break;
case 1: System.out.println("Case 1 ");
try {
Runtime.getRuntime().exec( "rundll32 url.dll,FileProtocolHandler " + DateiChooser.uebergabe );
}
catch ( Exception e ) {
e.printStackTrace();
}
}
}Die rot markierten Passagen gefallen mir überhaupt nicht.
Das mit dem .trim() bzw. replace funktioniert überhaupt nicht. (siehe Anhang)
Es muss doch eine bessere Lösung geben, wie diese beiden Arrays zu vergleichen.
Hab mich jetzt schon stundenlang mit Arraylists, Hashmaps, zweidimensionalen Arrays usw herumgeschlagen. Ich checks einfach nicht.
Kann mir jemand evtl sagen, wie die Methode besser zu strukturieren ist?
Im Anhang mal die Ausgabe der Konsole mit dem Popup der doppelten Einträge.
mfg
Maddin
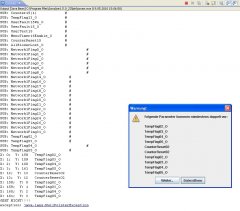
") , wenn ein Objekt in eine Set eingefügt werden soll, dass schon vorhanden ist, dann wird es einfach verworfen und die add()-methode liefert ein false zurück. Das ist schonmal eine gute Methode um Duplikate von vornherein zu vermeiden.
, wenn ein Objekt in eine Set eingefügt werden soll, dass schon vorhanden ist, dann wird es einfach verworfen und die add()-methode liefert ein false zurück. Das ist schonmal eine gute Methode um Duplikate von vornherein zu vermeiden.") Macht es aber nicht. (außer ich mache es falsch - siehe den Test mit den ' # ' in meinem Screenshot.)
Macht es aber nicht. (außer ich mache es falsch - siehe den Test mit den ' # ' in meinem Screenshot.)