Matze
Weltenwanderer
Hi.
Ich arbeite gerade an einem Programm, dass die Daten zweier MySQL Tabellen vergleichen soll. Die Tabellen sind von der Struktur her gleich und haben einen Primärschlüssel.
Ich weiß jetzt allerding nicht so genau, wie ich den Verlgeich angehen soll. Am ende soll eine Liste mit allen sich unterscheidenden Datensätzen (aber gleichem Primärschlüssel), eine Liste mit Daten, die nur in der einen Tabelle vorkommen und umgekehrt.
Die Tabellen können auch seeehr groß sein, deshalb weiß ich nicht wie ich da am besten vorgehe.
Für Vorschläge währe ich sehr dankbar.
Ich arbeite gerade an einem Programm, dass die Daten zweier MySQL Tabellen vergleichen soll. Die Tabellen sind von der Struktur her gleich und haben einen Primärschlüssel.
Ich weiß jetzt allerding nicht so genau, wie ich den Verlgeich angehen soll. Am ende soll eine Liste mit allen sich unterscheidenden Datensätzen (aber gleichem Primärschlüssel), eine Liste mit Daten, die nur in der einen Tabelle vorkommen und umgekehrt.
Die Tabellen können auch seeehr groß sein, deshalb weiß ich nicht wie ich da am besten vorgehe.
Für Vorschläge währe ich sehr dankbar.
 Ansonsten einfach nochmals nachfragen
Ansonsten einfach nochmals nachfragen")
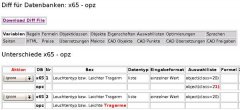
") Einer der wenigen MySQL Befehle die ich noch fast nie verwendet habe.
Einer der wenigen MySQL Befehle die ich noch fast nie verwendet habe.